
On March 14th, we encountered an incident involving incorrect grouping of different incidents. Our postmortem has some extensive details for all our users. At Spike, we are committed to alerting you when things go awry so it’s only fair we keep it absolutely transparent regarding any incidents.
Summary
From 12th March 2024, 11:00 PM UTC, incidents began to be grouped incorrectly, resulting in them being assigned the same public-facing ids known as counterIds. The issue surfaced when a user reported a discrepancy on our dashboard at 1 AM UTC on 13th March 2024. Within two hours, Damanpreet and Kaushik convened to tackle the issue, uncovering the strange grouping and mix-up in counterIds.
For instance, though incident example-123 was alerted, a previous incident was displayed on the dashboard instead.
Our database tracks all occurrences, differentiating repeated events through a boolean flag labeled latest. Typically, when an event reoccurs, its predecessor is flagged as false, enabling the new occurrence to assume the same public identifier. However, the situation reported by our user featured two events simultaneously flagged as latest, causing confusion.

Upon analyzing our database of nearly 15 million records, we identified that 7 customers and 26 incidents were affected. Although it’s evident that alerts for some incidents weren’t dispatched, a detailed investigation with our vendors is required to learn the full scope. Worst-case scenario, it’s possible that alerts for all 26 incidents were failed to be sent.
This incident has been classified as severity SEV2 with P1 priority.
Leadup
The latest flag was introduced in the initial version to handle the grouping and reopening of incidents. In the past two weeks, we updated the grouping logic during regular maintenance. This introduced a bug that incorrectly left the latest flag set to true.
This oversight led to a domino effect. It caused issues with CounterIds being skipped or reused. When one incident failed to update the flag, it affected subsequent incidents by improperly grouping CounterIds.
Impact
Our post-incident analysis revealed that 7 customers and 26 incidents were affected. It appears that alerts for these incidents may not have been sent.
Detection
An issue was first brought to our attention by a user at 11 PM UTC on March 8th, 2024. We promptly conducted an investigation and applied a temporary solution that initially proved effective.
Realizing the need for a deeper analysis, we turned to Warden, a service within Spike engines designed to detect anomalies in incident data. This helped us identify if similar issues were affecting other users.
Response
Damanpreet led the response and began the initial investigations. Within hours, we all joined to understand the data and identify the root cause.
Putting Spike to good use
We launched a new service, Warden, on Spike for Slack alerts. This setup instantly notifies us whenever Warden spots patterns similar to newly triggered incidents.
Starting March 13th, these alerts have been crucial. They flagged multiple incidents impacting a few users, enabling us to respond swiftly. Thanks to Spike alerts and the detailed data from Warden, we were quick to trace and export the necessary logs.
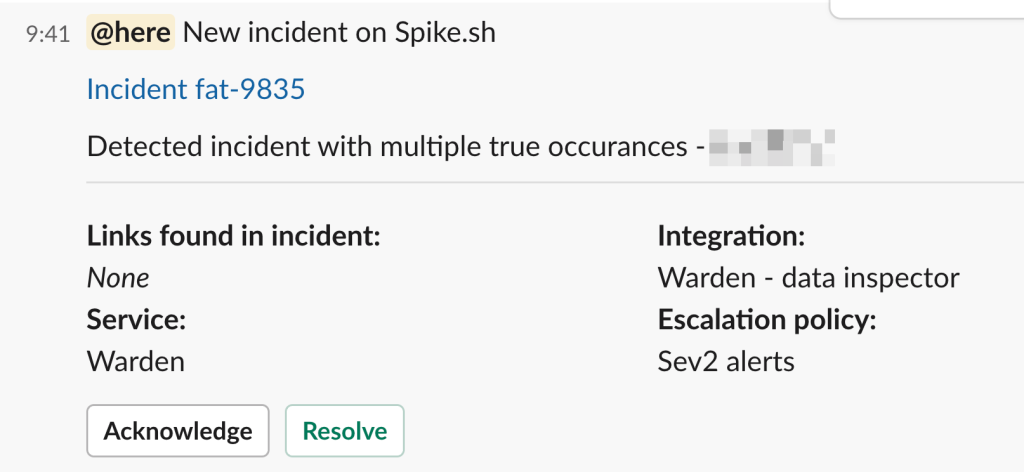
By then, a pattern began to emerge, highlighting the effectiveness of our new system.
Recovery
We began our recovery by removing flag dependencies and cleaning up our incidents collection. This process left us with a main collection of only unique incidents and moved all past occurrences to a new History collection.
The History collection is structured to store a complete snapshot of each incident as it happened, including details like priority, severity, and mute status. This makes it easier to work with and learn from our historical data.
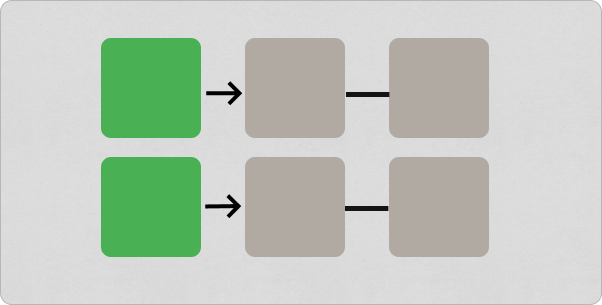
Data cleanup ftw.
Lessons
Some key lessons
- Maintaining flags by collating duplicate data in one collection is painful to maintain.
- Clean, organised data is underrated.
- Better performance, data redundancy, and maintenance overhead needs to be primarily kept in mind while scaling.
Closing note
Our past architectural decisions were well-suited for our initial scale, supporting our growth phase. We’re been on a roll on rebuilding and enhancing several services for greater scalability. Opting not to over-engineer initially was a good choice, it gifted us with flexibility and agility.
This evolution also doubles down on continuous improvement and readiness for future challenges. Our apologies to all our users 🙏




