Over the last couple of years, Spike.sh has largely been a Simple Incident Management Platform helping engineering teams across the world. Our focus on simplicity has been well received by all of you and we couldn’t be more happy about it.
After speaking with users earlier this year, we quickly realised there is a lot we can do to help our responders and help them better than we currently are.
In this blog post, I am pinning down our journey into becoming a more Powerful Incident Management Platform helping responders take quicker actions.
Our journey
Our journey begins with understanding problems first and then trying to find solutions that can help our users.
Few of the several questions from speaking to our customers which gets translated into problems were –
- Should I care about this incident alert now?
- Is fixing this incident a high priority?
- Is this really an ongoing incident?
- Am I the only person looking into this?
- Are we seeing this incident for the first time?
- How did we resolve this in the past?
- How do I communicate my findings about this incident?
- I would like to change the incident title so it makes more sense, can I do that?
When we were whiteboarding ideas, it seemed like a lot of them were far-fetched and many just must-haves. So, we selected our must-haves and got down to work.
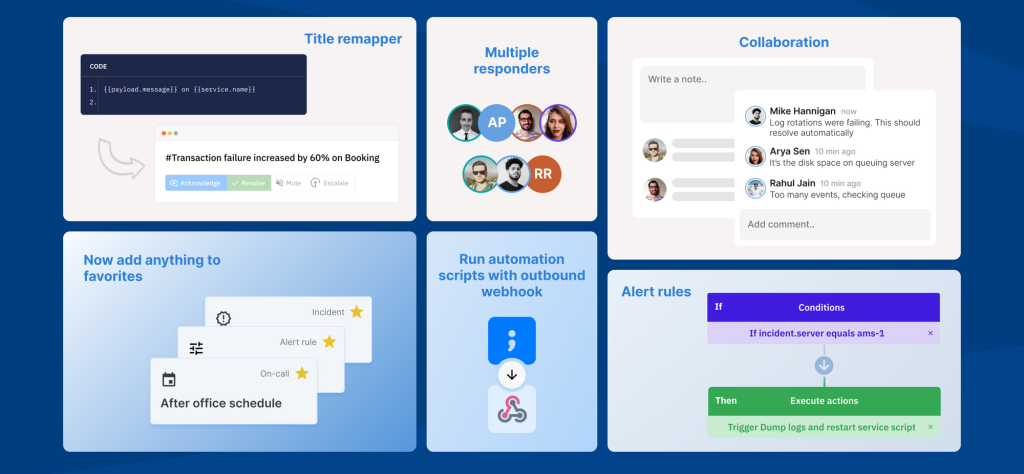
1. Multiple responders
Problem: If incident management is a team effort then why is there only one responder per incident on Spike.sh?
The ability to add multiple responders was an essential one. Especially considering that resolving an incident is not a one-person job, it’s a team effort.
So, in came multiple responders.
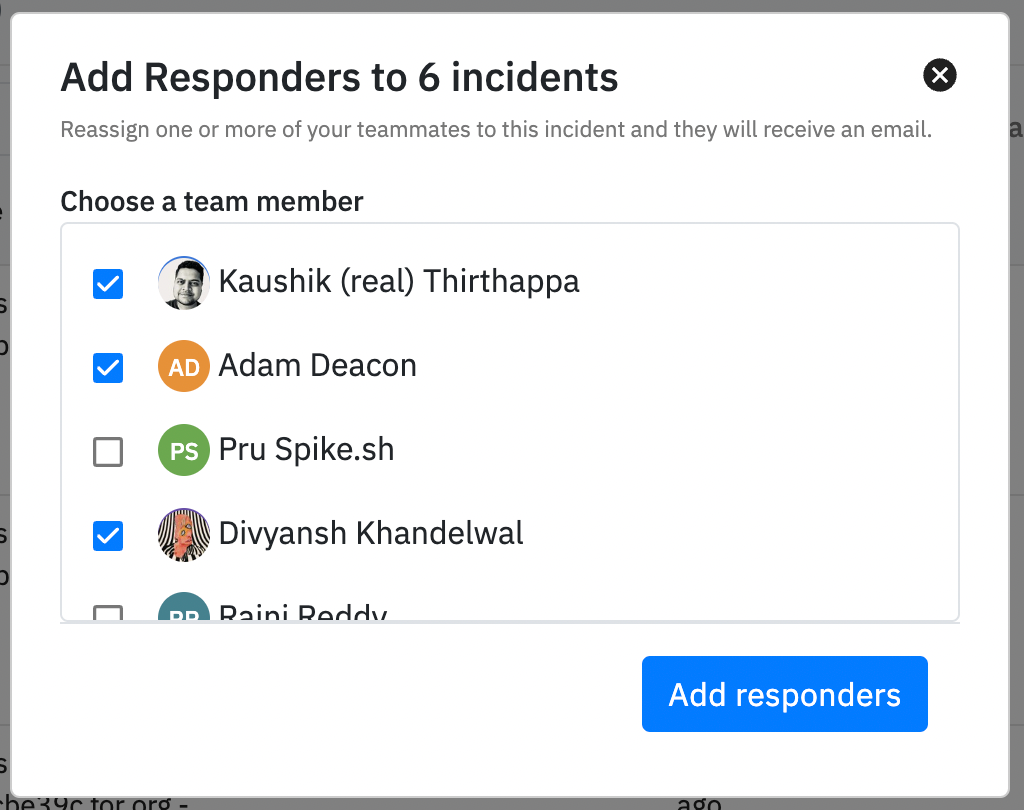
This is around the time that more and more customers had started to ask for better collaboration on incidents. We started digging in on how we could achieve this.
2. Collaboration
Problem: Multiple responders are having a hard time on collating the information on resolving incidents at a central place
To increase collaboration, we introduced Comments and Notes.
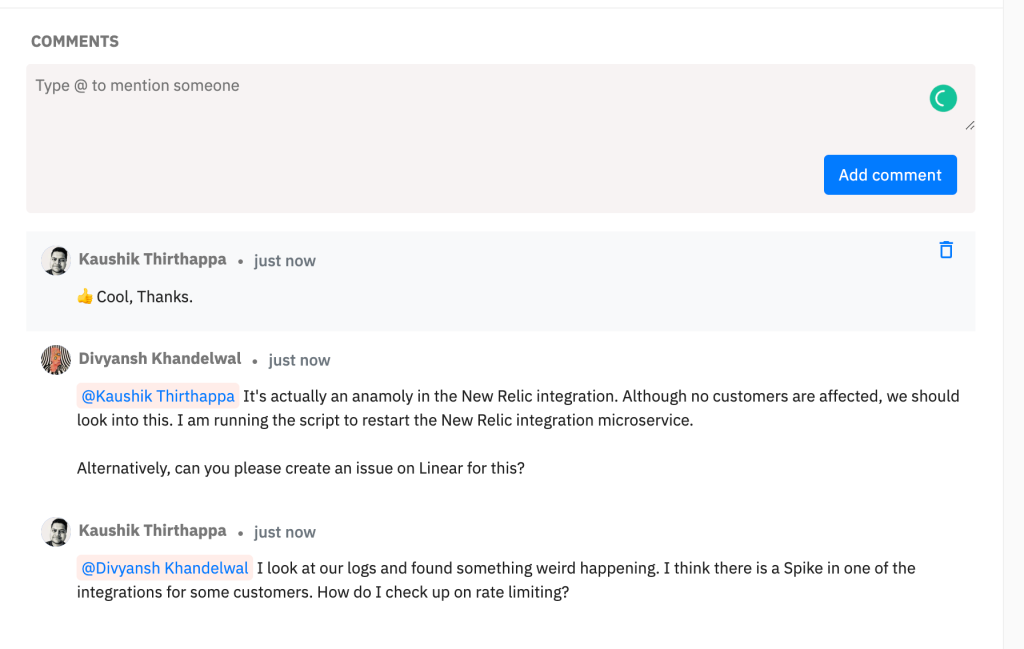
Commenting on integrations was a bold move for us because we always imagined that users would tackle all collaboration for an incident on Slack or Microsoft Teams but that kinda forces the notion of urgency. Besides chat disappears after a while.
Better collaboration also meant introducing profile pictures. Natural next step we felt 🙂
Along the lines, we also added Notes. Mainly, notes are being used by responders for the following use cases:
- What were your observations while digging in more about this incident?
- How did you resolve this incident?
Why should one leave notes to an incident?
If the incident repeats itself at a later point in time, it’s easier for responders to quickly check how previous responders had resolved this incident. Helps adding better context.
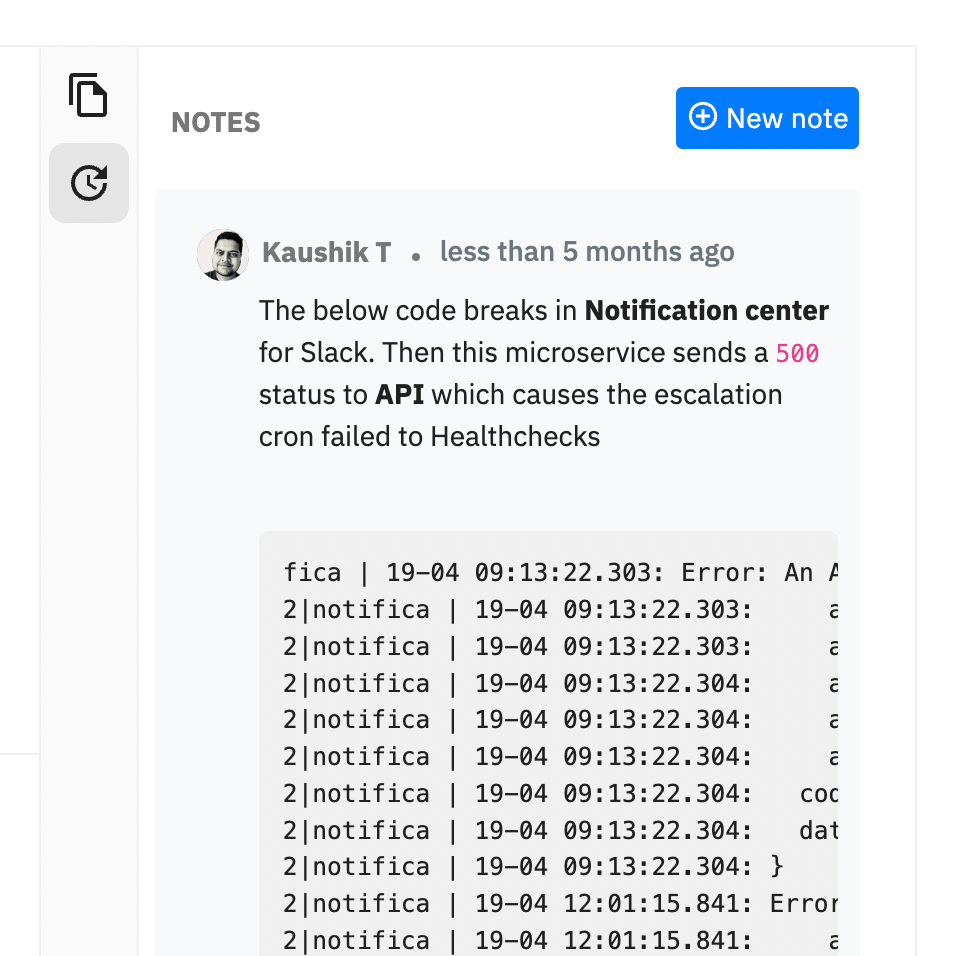
Notes will be perpetual to an incident and so would comments. This way when the incident triggers or repeats again, responders will have better context.
To accommodate this, we wrote a new logic layer to identify if an incident is repeating itself. Previously, we would create a new incident each time.
3. Better Incident Context while browsing incidents
Problem: There are so many incidents. Where do I begin?
This was also a customer request. The idea was to understand which incident needs more attention in a sea of incidents.
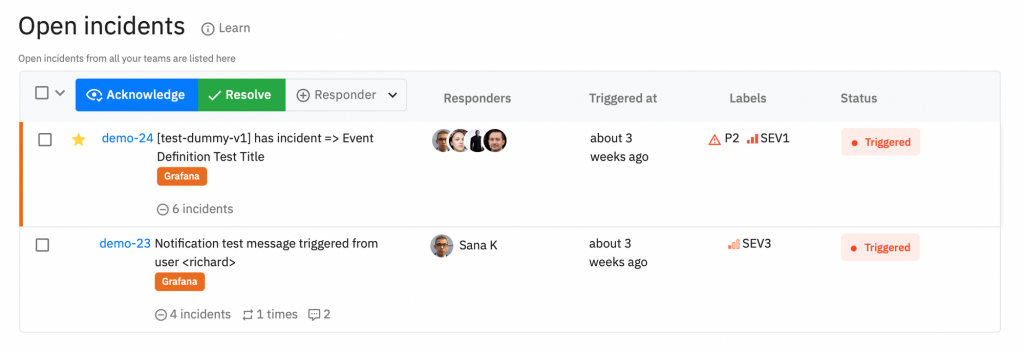
We powered the incident table with –
- Severity
- Priority
- Suppressed count
- Repeated count
- Total comments added
- Total notes added
- SEV1 incidents will have a distinctive line on the side
- Add and remove an incident from favorites
Without these pointers on the incident table, it was confusing for responders to understand which incident should they be looking at first.
Additionally we also added a single-click Incident context directly from the table.
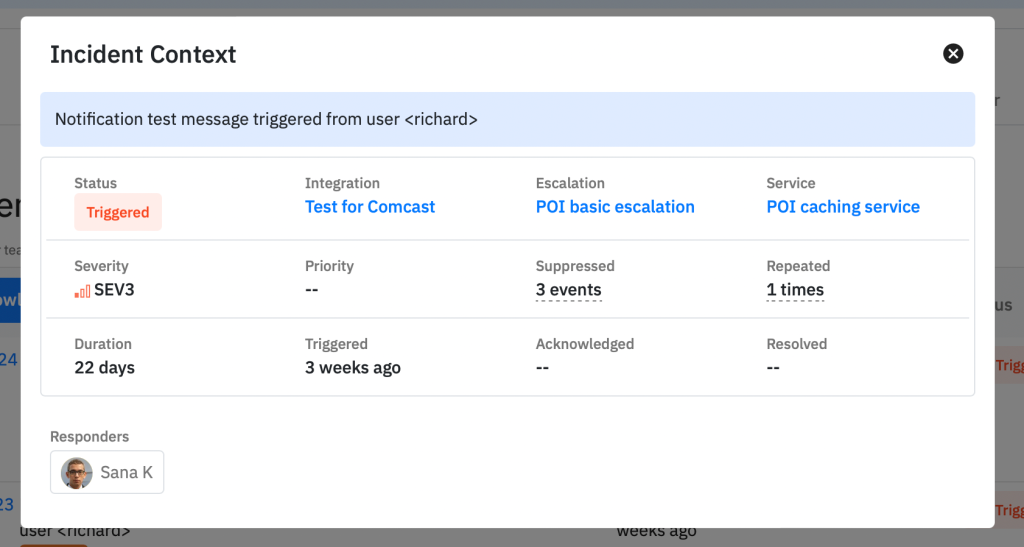
But how do we determine or set the severity and priority for an incident though? That comes next
4. Alert rules
Problem: Dynamically change escalation policy for critical incidents or avoid creating incidents if users are only testing
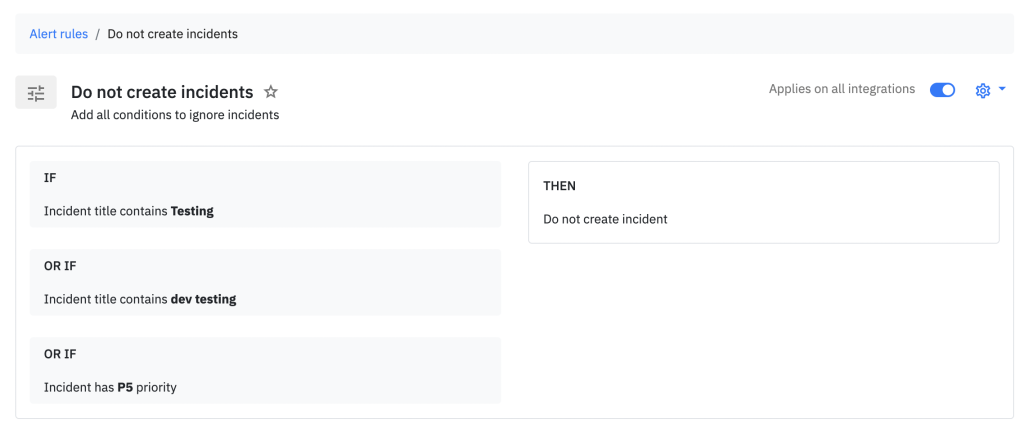
Alert rules come into play right before an incident is created. Here are the use cases we built it for ::
- Automatically set severity and priority
- Avoid creating an incident
- Change escalation policy (if incident is SEV1, change escalation policy to involve everyone)
- Trigger an outbound webhook (more on this later)
- Automatically acknowledge or resolve an incident (coming soon)
All this before the incident is created.
pro tip: Send severity or priority in your incident payload and we will set it automatically
5. Outbound webhook
Problem: We have an automation script that might resolve the incident automatically for an incident. Can we run that?
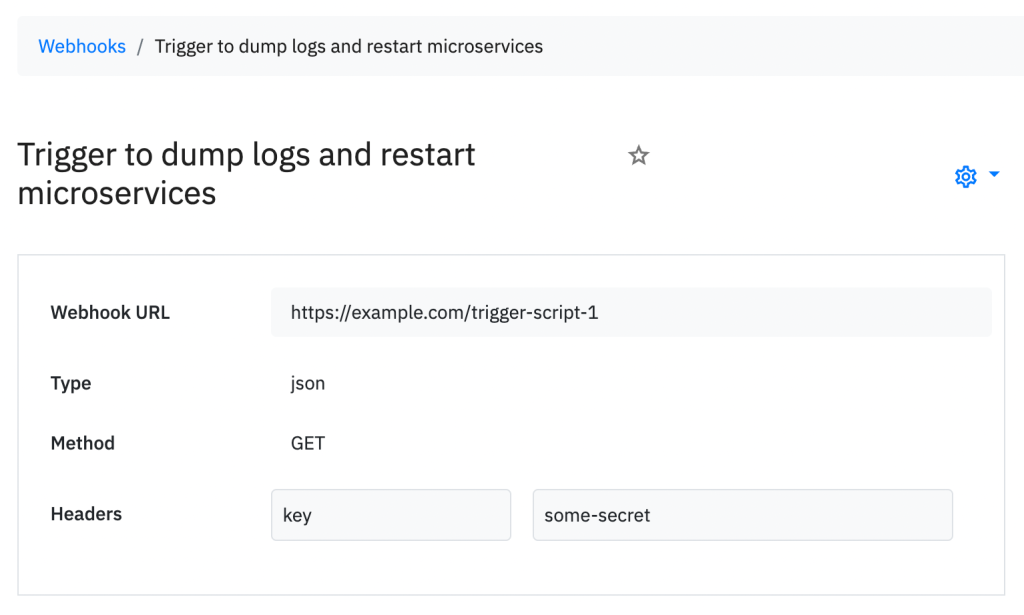
Some use cases we got from our users —
- Trigger a lambda function to dump logs
- send an automatic message to support team
- restart microservices
Outbound webhooks are any publicly and securely hosted URLs which we will trigger from alert rules based on specific set of conditions. The functionality of your script does not bother Spike.sh. We only trigger this.
A lot of users have begun to run scripts and automatically resolve incidents using outbound webhooks.
6. Title remapper
Problem: I fail to understand the incident when I get an alert. Can we change it to so it would make sense?
One of our customers has one Datadog account to monitor servers for all their customers. When an alert is received, they wanted the name of the customer in it. This is where the idea of Title remapper was born.
Each integration on Spike.sh is carefully built to convert JSON payload into Human-readable format. Sometimes, chances are the alerts don’t make sense. This is where Title remapper comes into play.
Users can programmatically write HandlebarsJS code to change incident title at run-time so alerts make more sense.
Read our blog on Title remapper
To speak with me or the team, ping us on chat from your dashboard or email me directly at [email protected].





