Software teams use cron jobs to handle many important tasks like database backups and maintenance scripts. Cron jobs make sure that your applications are behaving as they should, but cron job failures are often silent and not noticed until the problem becomes worse. In this guide, we will learn how to stay aware about cron job failures by using Healthchecks.
Create a new cron job check
First, sign up for an account on Healthchecks and create a new check. Healthchecks will create a check with default values which you can change based on your needs.
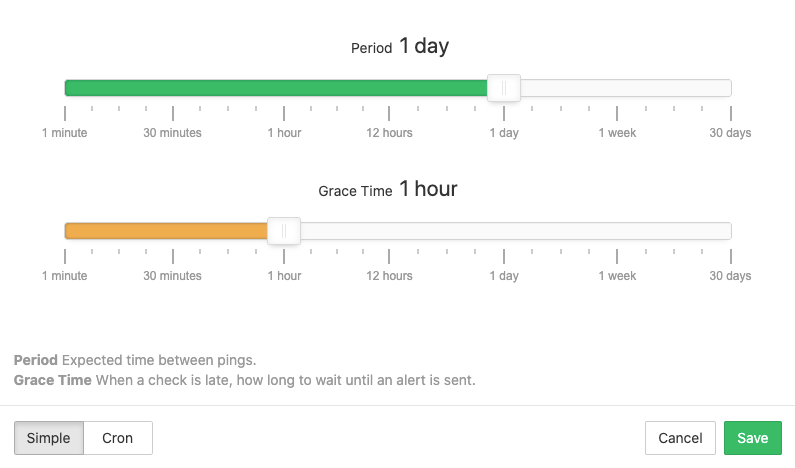
The most important part is adding the schedule of the cron job you want to monitor to the new cron check. Healthchecks provides a way to configure a simple repeating schedule (shown below). You can also use the cron expression from your cron job for more granular schedules. Tip: To create cron expressions easily, you can use Crontab guru in the future.
You can also specify a grace time, which is the amount of time Healthchecks should wait for a ping from your cron job before raising an alert. This can be helpful to avoid false alerts from cron jobs that take some time to execute.
Integrate Healthchecks in your cron jobs
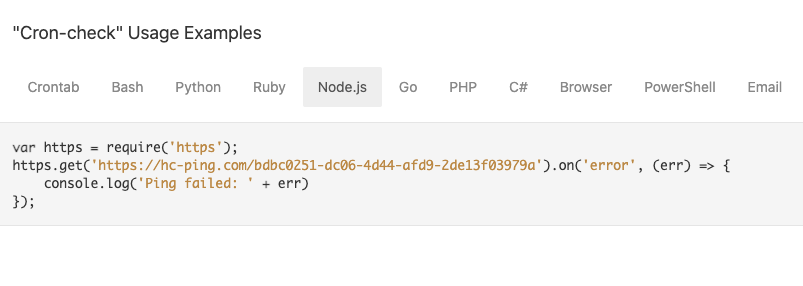
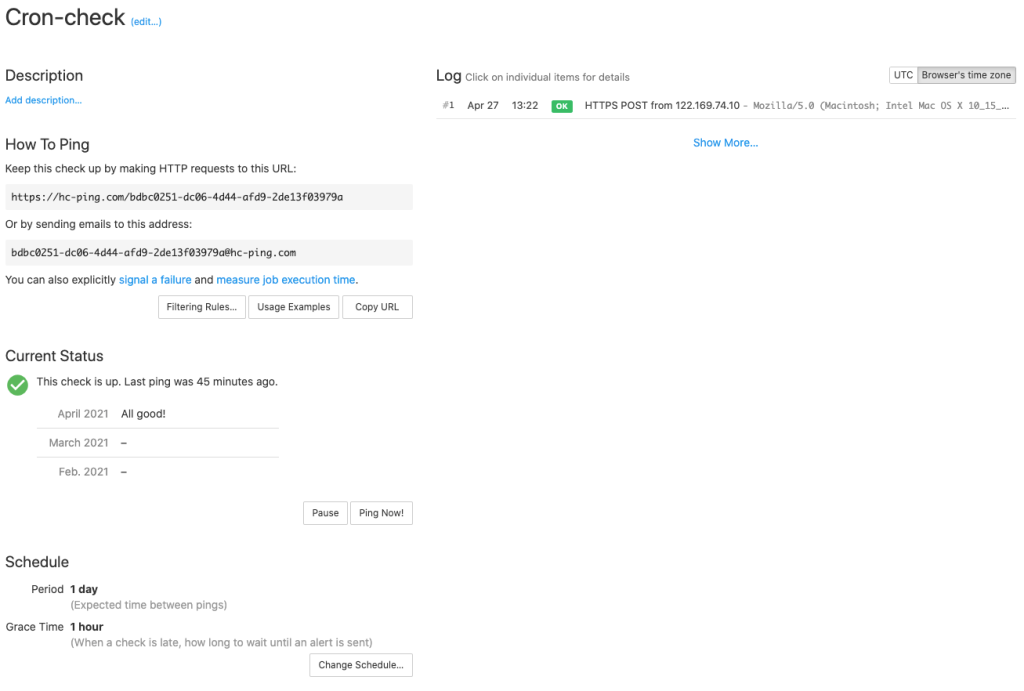
For Healthchecks to know if your cron job has passed or failed, you will need to communicate with Healthchecks inside your cron job. You can do this by pinging a unique URL for your cron check. Healthchecks provides code snippets for major programming languages to help you ping the cron check.
Healthchecks will start listening for pings from your cron job and will raise an alert if it does not get an expected ping based on your cron schedule. You can also signal cron job failure to Healthchecks by pinging the fail URL for your cron check.
If you don’t want to ping the URL, you can also communicate the success of the cron job by emailing a unique email address for your cron check.
Measuring run times
You can measure the running time of your cron jobs by telling Healthchecks when your job starts. This can be done by calling a start URL for your cron check at the beginning of your cron job execution. Healthchecks will calculate the running time by comparing with the complete ping from your cron job. You can then see the run time for all your cron job executions from the Healthchecks dashboard.
Alerts

To avoid issues because of unnoticed cron failures, you should set up alerting for your team when a cron job fails. You can use Spike.sh to alert your team about cron check failures on phone call, SMS, Slack and Microsoft Teams. You can also create on-call schedules in Spike.sh to assign first responders from your team on a rotating basis.
Conclusion
You can now start monitoring your cron jobs with Healthchecks and set up flexible alerting for it using Spike.sh. If you would like to know more about monitoring your entire production stack, drop us a line at [email protected].